
Dev Diary: The rise and fall of the zombie swarm
March 24, 2020 / Alex LintonDev Diary
Most traditional private messaging apps have a centralised server that lets you store and send all of your messages without a hassle.
But, for all the convenience that centralised servers offer, there’s always the chance whoever’s running them will end up screwing you over. You’ve just gotta hope the operator won’t snoop on your messages, share your conversations, or leak your information through a simple, honest error.
It’s these drawbacks that pushed us to use a decentralised network for Session. But, with no central server to easily store and relay messages between users, we’re sacrificing some convenience.
So, how do we deliver your messages without a central server?
Session uses things called swarms. Swarms are groups of 5-7 Service Nodes (run by independent operators around the world) that are ‘connected’ to each other. When you create a Session account, your client will be assigned to a swarm. This way, if you’re offline when someone sends you a message, it can be stored in your swarm until you come online to retrieve it.
Generally, you won’t be in the same swarm as the person you’re trying to contact, so your client needs to find out which swarm your contact is in before you can send them a message. Then a copy of your message is sent to three different Service Nodes in your contact’s swarm — this gives some extra insurance that your message will be stored and delivered successfully.
Obviously, it’s critical that messages have guaranteed delivery. If one swarm handles 90 per cent of all messages, we’re going to run into some serious performance problems. But… Session is all about privacy — we don’t know anything about your messaging habits, so how can we make sure messages are distributed evenly across the network?
We needed a protocol that could reliably deliver messages in our network.
MISSION: To design a way to deterministically distribute the storage of messages approximately evenly across the Service Node network.
We knew our solution needed to be deterministically calculated — meaning anyone could join the network, follow a set of rules, and come to the same conclusions about any given swarm. But we had to make sure it wasn’t easy to predict which swarm a Service Node would end up in, otherwise a malicious actor could theoretically gain control of a whole swarm and cheat message storage tests (these are simple tests which Service Nodes use to ensure all peers in their swarm are storing messages correctly).
If one actor could reliably gain control of a swarm, they’d effectively get to choose whether your messages are ever delivered. That doesn’t sound very trustless, does it?
So, we needed to work out how to group all the Service Nodes into swarms in a relatively unpredictable way, and then find a way to evenly distribute users into those swarms. For now, we’re going to focus on the second part of this problem: how to distribute users into swarms.
We decided to map swarm IDs and user public keys onto the same number line, then assign users to the swarm IDs they were closest to on the line. Public keys are randomly generated for new users, but how should we create new swarm IDs?
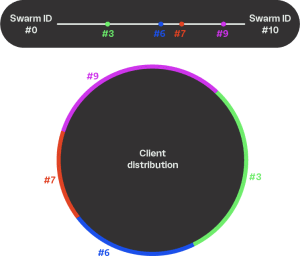
Imagine we have a swarm distribution that looks like this. Note: swarm #10 wraps around to swarm #0.

In this situation, swarms #6 and #9 are going to get way too much traffic — all the public keys mapped from 2 ½ – 6 ½ will be in #6, public keys from 8 – 2 ½ will be in #9, and public keys from 6 ½ – 8 will be in #6.
A new swarm can be created to lighten the load, but if we do randomly generate swarm IDs the way we do for public keys, we might end up with something like this:
As you can see, adding swarm #8 would solve nothing. Swarm #6 would still have all the public keys from 2 ½-6 ½ mapped to it, and swarm #9 would now have 8 ½-2 ½ — similar to before.
Of course, being random, the new swarm could just as easily pop up at #3 and solve the problem — but we needed a method which would work all the time. Next we tried making new swarm IDs fill the biggest gap on the number line. This way, we should get a more even distribution, like this:
Simulations showed a much healthier load distribution when we used this gap filling method, which always ensured the largest swarm would never be more than double the size of the smallest.
We implemented what we thought was a winning strategy, only to discover…our code was actually broken. We didn’t notice during our initial testing, because it was breaking in ways we couldn’t see. But when we were gathering some testnet statistics, we noticed that one of our scripts seemed to be suggesting more than 20 nodes belonged to a single swarm — very alarming! There should only ever be 5-7 nodes in a swarm.
Our system seemed to be working fine up until then, and we hadn’t touched any of the relevant code in months — so this was pretty confusing. All of a sudden, there was a serious problem right before release.
Turns out the algorithm itself was correct, and it was just a single line of code in the implementation causing all the trouble.
To figure out what was going on, we needed to see some historical data about swarm sizes. Unfortunately, that information didn’t exist: we didn’t have the relevant logs and the blockchain only stores the latest swarm state. To get the logs we needed, we were going to have to replay the whole blockchain for ourselves — from the very beginning.
When we did that, our reconstructed swarm assignment history showed nodes joining the pathological swarms seemingly out of nowhere. After looking at some other logs, it all clicked — they were decommissioned nodes.
We had recently introduced the decommissioned state — a kind of purgatory for nodes before they get deregistered. This way operators have a bit of time to patch up their unhealthy nodes before they’re lost for good. Decommissioned nodes were never counted towards swarm size — otherwise you could end up with a swarm full of faulty nodes.
Here’s the problem: decommissioned nodes automatically return to their original swarm if they come back online — completely bypassing swarm size limitations.
So, Nodes that were about to be decommissioned weren’t resetting their swarm ID values. That made the solution pretty simple: we had to reset the swarm ID value for nodes the moment they are decommissioned. Implementing this fix only required adding one line of code, but it took a couple of days to figure out.

On its own, the oversized swarms would probably just add some inefficiency to the network, but there was another, more insidious problem.
By design, if the size of a swarm gets dangerously small, the network might redistribute the swarm’s healthy nodes — essentially removing the swarm. What would happen if a single decommissioned node were to come back into a swarm that no longer existed?
We called it a zombie swarm — a swarm brought back from the brink. Before the patch, the network would allow the swarm to operate even if it only had one node — far too small for it to be considered reliable.
But thanks to our one-line fix, our release went ahead as planned and the zombie swarms never took over.
We ran into a lot of problems trying to come up with a dependable decentralised message delivery system.
For all the headaches along the way, in the end all we needed was that one line of code — to fix the zombie swarm dilemma — for everything to fall into place.

The Future of Session
June 15, 2026 / Session

A Personal Appeal From Cofounder of Session - Chris McCabe
March 18, 2026 / Chris McCabe

Rotating keys for Session repos
January 22, 2026 / Session

Session Pro Beta update: December 2025
December 07, 2025 / Session

Session Protocol V2: PFS, Post-Quantum and the Future of Private Messaging
December 01, 2025 / Session

Removing screenshot alerts from Session
November 09, 2025 / Session